Google Search Central Paris 2026 : ce qu'il faut retenir (et ce qui reste sans réponse)
Retour sur l'événement Google Search Central à Paris. Stratégie Discover, gestion du spam, IA et avenir des fonctionnalités de la Search Console : voici les points clés et l'analyse sans langue de bois de ce rendez-vous média.
, publié par largow',530,620)){kind=link}
Publié le 26/06/2026
Mis à jour le 29/06/2026
")
Nous étions environ 200 "happy few" à nous rendre ce 25 juin 2026 par une chaleur écrasante dans les locaux de Google France à Paris afin s'assister au tout premier Google Search Central Paris 2026.
S'y trouvait la crème de la crème du SEO média, mais aussi des SEO freelance ou agences, et des agences media.
Contrairement à l'évènement du même nom et qui se tient à Zurich (et dans de nombreuses autres villes dans le monde, récemment à Milan), celui-ci était beaucoup plus court (une petite demi-journée) et très différent sur le fond et sur la forme. D'abord parce qu'il était entièrement tourné media, ce qui m'a beaucoup surprise, ensuite parce que nous étions moins nombreux, parce qu'il n'y avait pas de speakers externes à Google sur scène et parce que l'ambiance était beaucoup moins "cool" (c'est je pense lié au public présent dans la salle et peut-être à la chaleur).
La première information qui nous a été délivrée, c'est qu'il est trop tôt pour partager une date de deploiement concernant AIO (AI Overviews) ou AIM (AI Mode) selon la direction des partenariats news de Google France. A peine arrivés, on est déjà douchés. Il y a quelques jours, j'ai répondu sur LinkedIn que les rumeurs de déploiement dans les semaines qui viennent ne me semblaient être que de rumeurs. Cela semble se confirmer, quoique que d'aucuns m'affirment que l'info est solide et provient de sources de première main.
Martin Splitt et Daniel Waisberg avaient fait le voyage depuis Zurich (quel courage dans cette touffeur...), et John Mueller était connecté en visio depuis Mountain View.
Comment le Search fonctionne / Comment le Search utilise l'IA
C'était la première conférence de l'après-midi. Ont été évoqués les basiques du crawl, de l'indexation, du rendering Google.
Google nous indique que tout le contenu d'un site ne sera pas indexé, que le volume et les urls indexés, cela reste mouvant et que c'est normal : si les utilisateurs trouvent un contenu moins utile, il peut au bout d'un certain temps être retiré de l'index.
Google nous rappelle qu'aucun site ne dispose d'un "traitement de faveur".
Google nous redit que le Search IA amène des visites sur nos sites plus qualitatives. Je ne pense pas qu'une étude l'ait prouvé à ce stade et il n'y avait pas de chiffres pour appuyer cette affirmation.
Google nous redit également que notre contenu, quelle que soit la manière dont il a été créé, doit avoir une valeur ajoutée.
Une punchline nous a même été délivrée : « We don't care who wrote the content ». C'est d'une certaine manière assez violent quand on parle de contenu journalistique… Et pas totalement vrai puisque les signatures/auteurs sont activement prises en compte, et rentrent dans le calcul EEAT, comme l'ont révélé les leaks.
On nous a ensuite expliqué ce qu'est un "commodity content » et un « non commodity content ». Là encore, c'est du connu, mais peut-être pas par tout le monde.
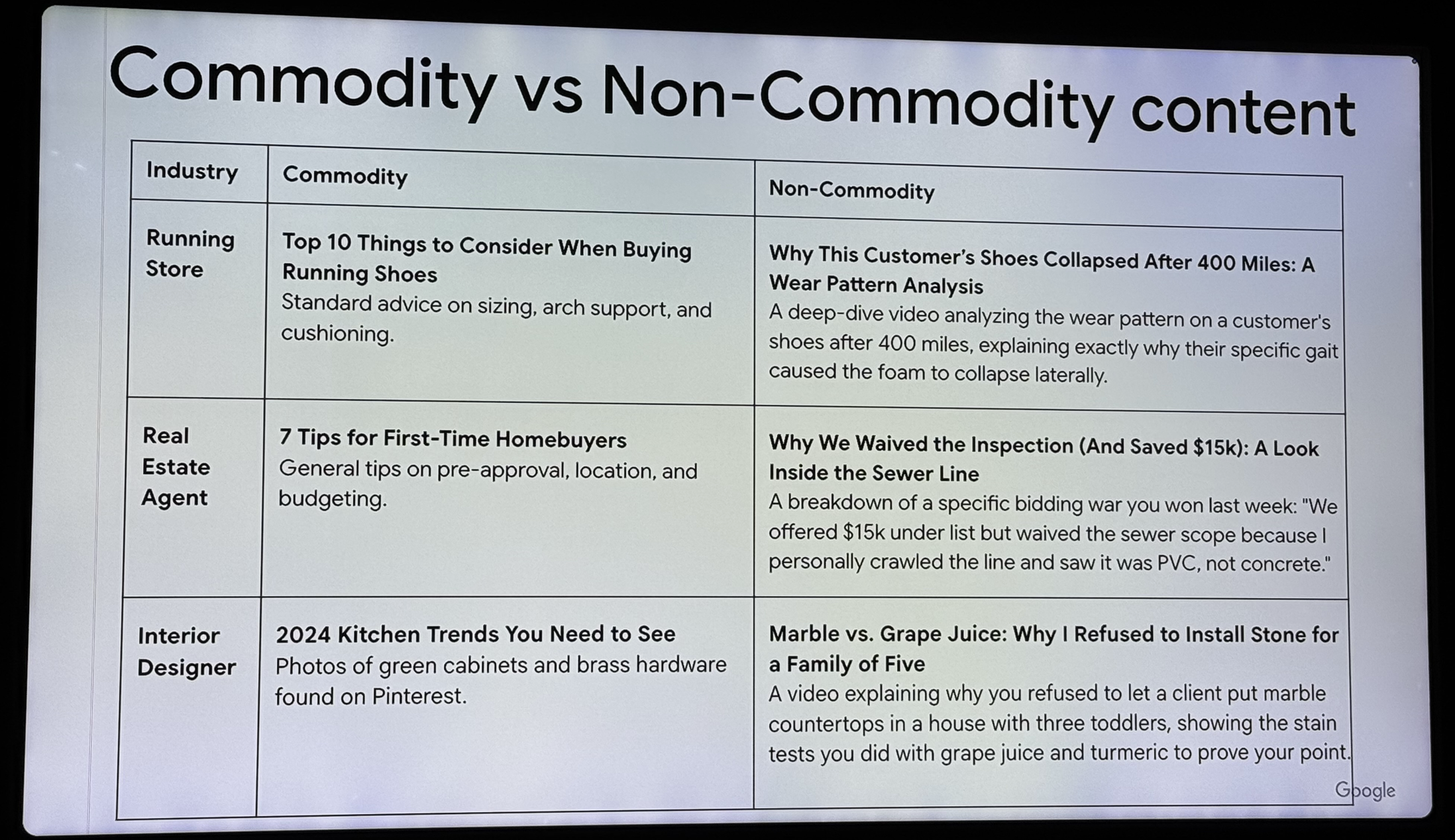
Que faire face à ce nouveau search :
- Produire du contenu de qualité
- Très bonne optimisation technique, dont webperf
- Explorer d'autre verticales comme shopping, local, vidéo, images

Les utilisateurs ont de nouvelles attentes, les évolutions de Google vont dans ce sens. Une illustration de cela : Google Lens. Nous devons nous adapter car 1 requête sur 6 n'est plus une requête textuelle aujourd'hui.
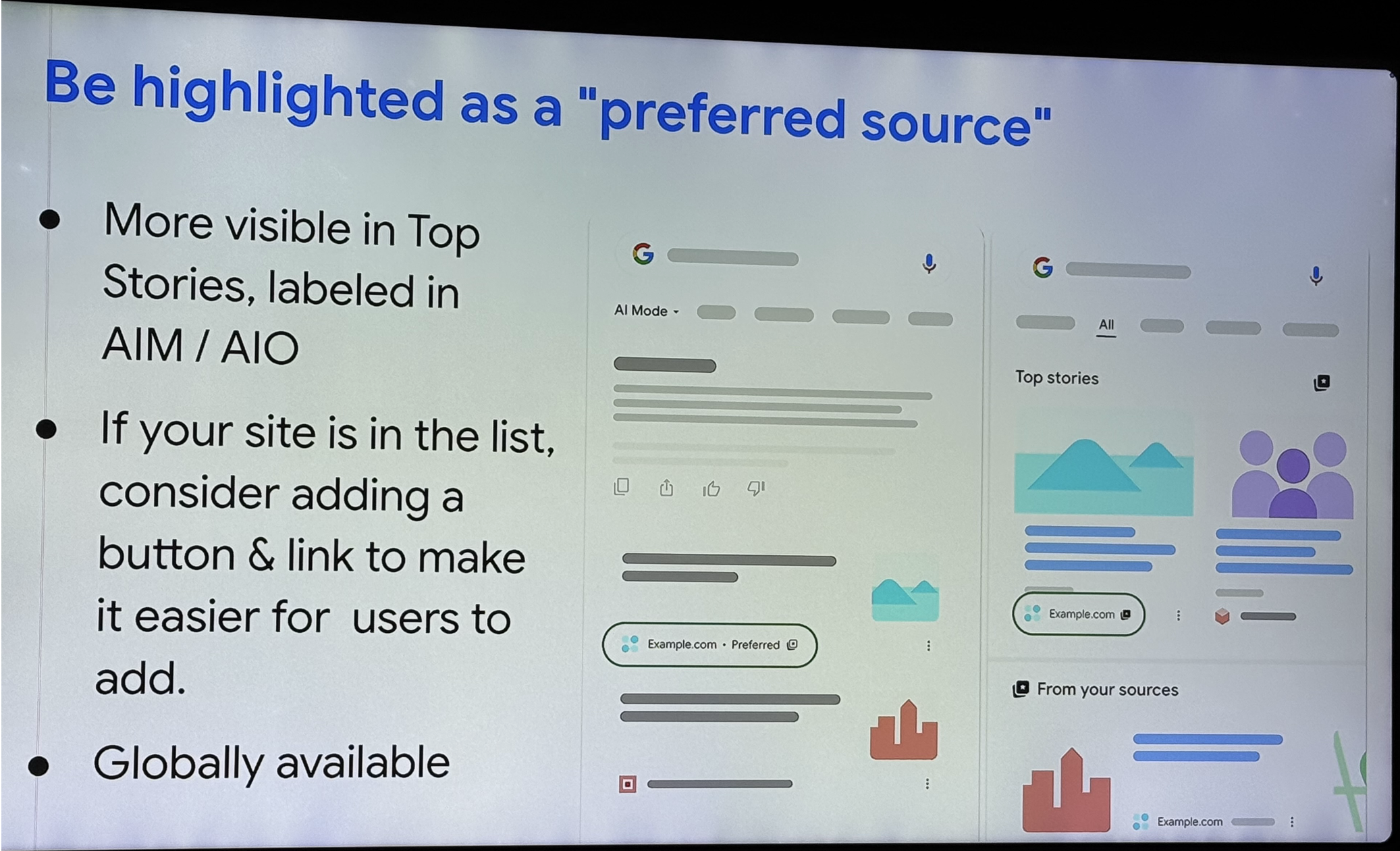
Google nous présente très brièvement sa nouveauté « Preferred source » pour les media et nous propose d'ajouter un bouton sur notre site si la page existe. Ils ne nous précisent cependant pas pourquoi un site peut ne pas avoir sa page Source activée ni pourquoi.
Ils nous annoncent 34% d'engagement en plus pour les users qui ont ajouté un site comme « source préférée ».
AIO/AIM: focus sur les nouvelles fonctionnalités (indisponibles en France)
Cette session, prévue au programme n'a finalement pas eu lieu
Les sources de data Search et les nouveautés de la Search Console
La première partie de cette session était identique avec celle qui avait eu lieu à Zurich en décembre dernier, la seconde était nouvelle.
Google nous précise qu'il y a 3 sources de search data : Google analytics, Search console, Google trends
Ces 3 outils ne présentent pas les mêmes data. Il y a des moyens de les comparer entre eux, mais pas toutes, et pas toujours sur les 3 outils.
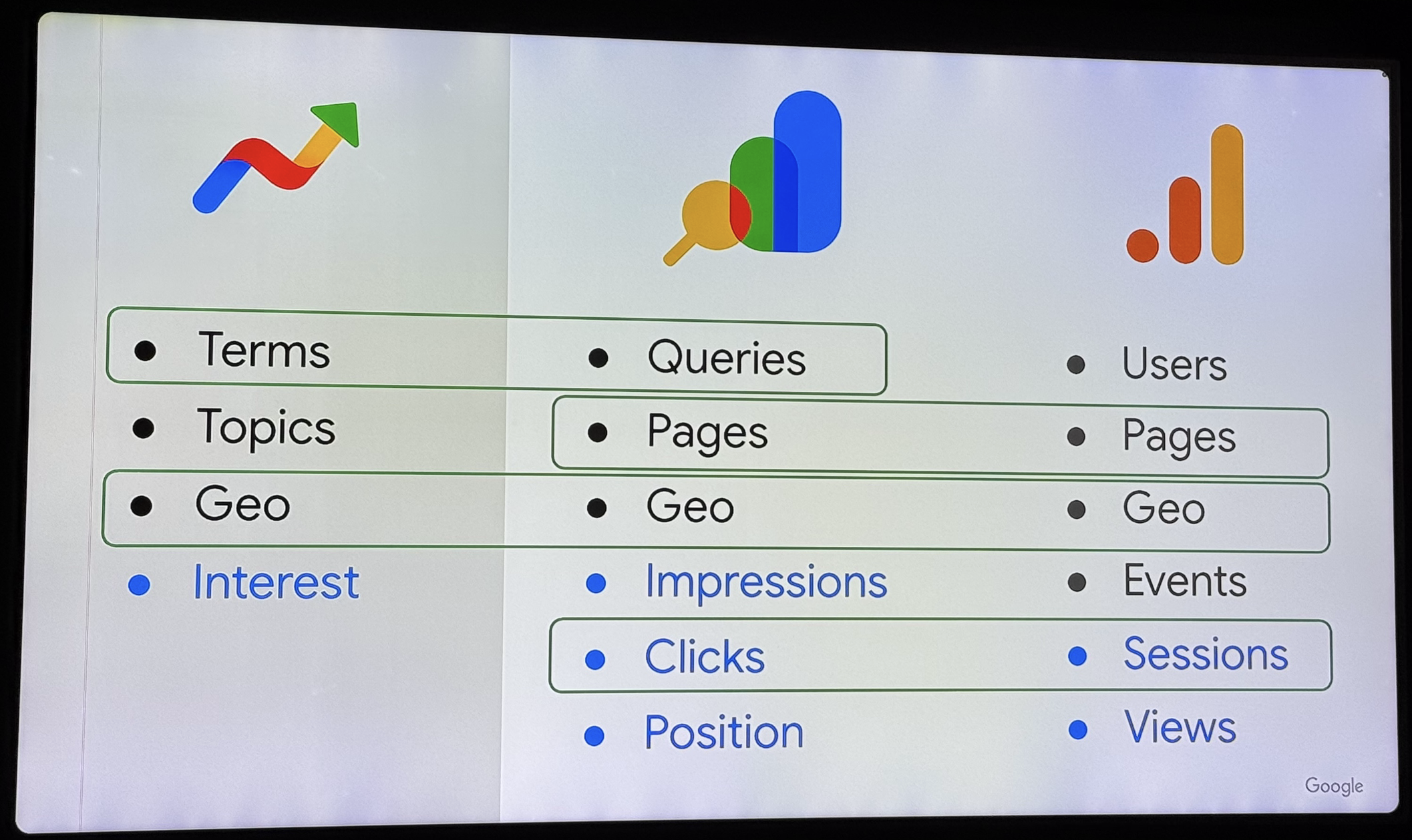
On nous redit qu'il n'y a pas de porosité entre les data GA et le search.
3 fonctionnalités récentes de la Search console
1. Query groups : pour grouper des mots clés avec ses misspellings et ses variantes (déjà présentée à Zurich en décembre
2. Al powered configuration
3. Generative Al features Beta
Ces trois fonctionnalités avaient été présentées à Zurich en décembre, puis largement diffusées depuis par la presse. Mais peut-être que c'était un rappel utile car j'ai vu pas mal de gens dans la salle prendre des photos.
Les reports AIO/AIM dans la GSC
Ils ont été lancés en bêta il y a 2 semaines. Ils contiennent :
- Impressions
- Pages
- Countries
- Devices
De l'IA dans Google trends
Un panneau Gemini a récemment été ajouté dans l'outil. J'étais passée à côté de cette info.
Maximiser Discover : Stratégie et best practices
C'est sans doute la session que nous attendions tous les plus. Voici Les points à retenir.
Les évolutions récentes de Discover avec l'insertion de contenu social media
L'ajout de contenu UGC dans Discover correspond à ce qu'attendent ceux qui ont des centres d'intérêt. Les posts Instagram, Twitter/X etc. adressent ce besoin
Le problème du spam
Il n'a absolument pas été nié et même reconnu dans son ampleur. Comme à Zurich en décembre, Google cite les articles de Jean-Marc Manach de Next.

L'équipe trust and safety (une représentante est venue de Sunny Valle pour cette présentation) traite les feedbacks utilisateurs sur la qualité des contenus afin de lutter contre cela : utiliser la fonction dans Discover quand vous voyez un article problématique a donc un véritable intérêt car c'est lu par un ingénieur, via un traitement IA par lots.
Pour lutter contre le spam, Google commence à utiliser des signaux issus du search en plus des feedbacks utilisateurs (entre les lignes : EEAT, filtre YMYL). Rien ne nous a été précisé en ce qui concerne le déploiement de ces signaux hors des USA (cf. le Core Algo Discover de janvier dernier).

Il y a aussi énormément de spam en Inde, bien plus qu'en France en réalité : contenu NSFW, fausses infos sur personnes mortes, produits qui n'existent pas, etc. NDLR : un ingénieur de Google me disait fin 2025 que la France et L'inde étaient les pays les plus touchés au monde par le spam Discover. NDLR 2 : on a déjà parfois ce genre de problème en France, hors Discover, via des réécritures sauvages des balises meta description dans les SERP's cette fois).

C'est pour lutter contre cela que le premier Core update Discover a été lancé (NDLR : en janvier, USA only à ce stade).
Si vous êtes un publisher qualitatif qui a commis une erreur, ils se disent prêts à accueillir le site à nouveau (via une demande de reconsidération via la Search Console - Cela ne s'applique que pour le cas où vous avez reçu un message explicite dans la GSC faisant état d'une pénalité). NDLR : ce qu'ils ne précisent pas c'est que la réintroduction ne se fait jamais à trafic ISO versus avant la pénalisation.
Il y avait peut-être ici un message caché aux publishers présents dans la salle : si vous faites acte de contrition, on veut bien vous pardonner car on a besoin de contenu de qualité journalistique ?.
Ils utilisent l'IA pour traiter les feedbacks users et lier ces signaux aux signaux issus du search. Cette information-ci est particulièrement intéressante. A mon avis là encore, c'est "US only" à ce stade.
Les conseils pour optimiser pour Discover par Google : c'est du connu, rien de nouveau
Il n'y avait strictement rien de nouveau ici donc je vous en épargne le récit : images HD, bon contenu
Une précision : l'IA n'est pas un problème dans la production de contenu. Ce qui l'est c'est le spam.
Séance de Q&A
Google avait invité les participants à poser leurs questions en amont, en nous précisant bien que toutes les questions commençant par "quand" n'obtiendraient pas de réponse. Aucune des miennes n'a été sélectionnée, ça doit être pour ça ?.
Comment signaler clairement à Google les parties gratuites et payantes d'un article sans nuire à la visibilité dans les résultats de recherche et les réponses IA ?
La méthode préconisée est l'utilisation des données structurées pour marquer précisément les zones derrière un paywall ou soumises à restriction d'accès. Si le contenu complet est accessible lors du crawl avec le balisage approprié, Google peut le prendre en compte. Il est toutefois recommandé de trouver un équilibre pour ne pas nuire à l'expérience utilisateur, ce qui pourrait impacter la perception globale du site.
On a de fait déjà toutes les réponses dans la documentation en ligne.
Quelles configurations de paywall (meterred, hybride, freemium) sont les plus compatibles avec la visibilité dans Google Search pour un site d'actualité ?
Tout fonctionne pour peu d'avoir les bonnes données structurées et l'implémentation technique SEO correcte. J'ai été surprise par cette question, tant de mon point de vue c'est aujourd'hui maitrisé par tous les media.
Jusqu'où un média peut-il utiliser l'IA générative dans son flux éditorial sans que le contenu soit perçu comme étant à faible valeur ou généré en masse ?
Si la question était "comment je peux spammer sans que ça se voie? " la question était un peu gonflée ?. Google se concentre sur la qualité finale du contenu publié, et non sur la méthode de production. L'IA est utile pour le brainstorming, la synthèse ou la correction. Le problème survient lorsque l'IA est utilisée pour générer massivement des pages sans réelle valeur ajoutée, ce qui devient un risque pour le site
Précision d'un officiel de Google : le contenu de basse qualité peut tout aussi bien être humain. (On est bien d'accord sur ce point).
On nous précise cependant : attention, la manière dont Google gère le contenu IA pourra changer dans le futur. C'est je crois un avertissement clair.
Existe-t-il des statistiques sur le nombre d'utilisateurs ayant ajouté un site à leurs sources favorites dans Google ?
Le site va se positionner mieux sur ceux qui vous suivent selon les officiels de Google interrogés mais ne partagent pas de data dans leur réponse. (NDLR : je ne pense pas que les personnes présentes avaient ces informations en fait, sur une fonctionnalité très récente de surcroit).
Actuellement, il n'existe pas de rapport spécifique dans la Search Console sur le nombre d'abonnés ou de favoris. Bien que le fait d'être une "source préférée" puisse influencer la visibilité pour ces utilisateurs spécifiques, ces effets indirects sont déjà visibles via les impressions dans les rapports de performance. L'ajout d'une telle métrique est une suggestion qui sera transmise aux équipes produit
La fourniture de contenu en Markdown offre-t-elle un avantage pour les moteurs IA ou les agents ?
Aucun impact, c'est leur réponse officielle. NDLR : Cela peut être cependant vrai pour Google, mais pas pour tous les LLM...
NDLR : La markdown est un langage de balisage très léger, devenu "trendy" récemment avec l'optimisation LLM. Au lieu d'utiliser du code HTML, on utilise des caractères simples pour formater le texte. Le format est souvent utilisé par les développeurs pour rédiger des documentations techniques ou des fichiers Readme.
LLM.txt or not
Le fichier ne sert à rien
Pourquoi les données de la Search Console sont-elles limitées à 16 mois d'historique ?
Pour pouvoir comparer Q1 au Q1 de l'année dernière.
(NDLR : La vraie raison c'est le coût à mon avis... Utilisez BigQuery et stockez sur nos serveurs les data pour vous affranchir de cela)
Quel est le calendrier de déploiement pour les mises à jour majeures et les fonctionnalités IA ?
Ils travaillent sur un lancement global, mais pas de planning à nous donner.
Google ne communique pas de calendrier prédictif. Le déploiement dans une organisation de cette envergure dépend de nombreux facteurs régionaux et techniques. Lorsqu'une fonctionnalité est prête, elle est annoncée ; il n'y a pas de roadmap publique pour ces évolutions
Comment expliquer les fluctuations de trafic sur Discover et obtenir des directives pour améliorer les performances ?
Ce n'est pas inattendu. C'est lié à votre qualité de contenu.
La question n'a pas vraiment reçu de réponse en réalité.
Voici ce qui a été dit : Si une stratégie éditoriale glisse vers la production de contenu à faible valeur (spam généré par IA) pour obtenir des clics rapides, les utilisateurs s'en rendent compte et les signaux de qualité baissent. La solution est de rester une source de confiance : fournir des recherches approfondies, des citations transparentes, des images de haute qualité, et maintenir une expertise dans sa niche. Il est rappelé que la récupération après une perte de visibilité due à une baisse de qualité peut prendre plusieurs mois, voire plus d'un an
Pourquoi ne pas offrir un système de crawl par API permettant d'envoyer directement les données ?
Pour Google, crawler n'est pas un problème. Le problème c'est de trouver du contenu qualitatif.
La méthode actuelle de crawl reste la norme. L'indexation par API (Indexing API) est réservée à des cas d'usage très limités, comme les flux de données changeant en temps réel (offres d'emploi, vidéos live), et non pour l'envoi généraliste de contenu
Ça pourrait changer dans l'avenir mais pas pour l'instant.
NDLR : En sous texte : ce serait la porte ouverte au spam
Si chaque propriétaire de site devait faire une chose technique demain, quelle serait-elle ?
Ne bloquez pas Googlebot et ses autres crawlers ou au moins regardez vos logs pour vous assurer que vous ne bloquez pas ce qui doit être whitelisté par méfiance, car cela empêche ces derniers d'interagir utilement avec le site (ex: processus d'achat). Par exemple l'agent AI Google. NDLR : le message est reçu, loud and clear...
À propos des écarts de données dans les rapports de performance de la Search Console (notamment avec l'application de filtres) : quelle méthodologie adopter pour une analyse fiable, et faut-il systématiquement privilégier l'export BigQuery pour pallier ces limitations d'échantillonnage ?
TLDR; : Il faut utiliser Big Query pour récupérer une data non limitée. Avec les filtres, l'échantillon est rééchantillonné dans l'interface.
Google a confirmé que les écarts observés lors de l'application de filtres sont intrinsèques au fonctionnement de la Search Console. Ces mesures de protection (privacy et gestion des limites de stockage) ne visent pas à fausser l'analyse, mais à garantir la confidentialité des données. La méthodologie recommandée est la suivante :
-
Priorisation des données : Plutôt que de chercher à réconcilier parfaitement les totaux "bruts" avec les données filtrées, concentrez votre attention sur les tendances et les variations de performance. Si vous identifiez des groupes de requêtes à fort potentiel ou à fort taux de clic (CTR), ce sont ces segments qu'il faut isoler pour optimisation, même si les chiffres totaux ne correspondent pas au compte exact de votre base de données.
-
BigQuery comme standard pour les gros volumes : Pour une analyse fine et historique (au-delà des 16 mois), l'exportation vers BigQuery est effectivement la "best practice". Elle permet de s'affranchir des limitations de l'interface utilisateur, de croiser les données avec vos propres sources et de travailler sur des jeux de données complets, non échantillonnés, pour une précision chirurgicale sur les performances organiques.
Concernant les contenus sponsorisés, tribunes d'opinion et partenariats B2B : quelles sont les bonnes pratiques pour rester conforme aux politiques de Google sans nuire à l'image de marque d'un média leader ?
Google a précisé que leurs politiques n'imposent pas un "étiquetage" spécifique pour ce type de contenus
-
Gestion des liens : Il est important que Google puisse identifier les liens présents dans ces contenus comme étant sponsorisés. La pratique recommandée est d'utiliser l'attribut
rel="sponsored"sur ces liens -
Indexation : Si vous ne souhaitez pas que ces contenus (partenariats, tribunes) apparaissent dans l'index, vous pouvez techniquement les bloquer
-
Absence de règle spécifique : Il n'existe pas d'instructions particulières concernant le Search pour ces contenus au-delà de la gestion des liens. Cependant, les intervenants ont noté que les exigences pourraient différer pour Google News ou Discover, sans toutefois fournir de détails techniques précis sur ces points spécifiques
Comment identifier et prioriser, au sein des données de performance, les contenus à faible volume mais à forte valeur pour guider notre production éditoriale ?
Google a présenté une méthodologie utilisant un modèle de visualisation pour aider à orienter les efforts d'optimisation. Voici les points clés de cette approche :
- Utilisation des données Search Console : Un modèle (template) est disponible pour visualiser les données de votre site, où chaque "bulle" représente un mot-clé.
- Analyse des dimensions : La taille de la bulle indique le volume de clics, tandis que la couleur distingue le type de terminal (mobile ou desktop).
- Catégorisation des mots-clés selon Position élevée / CTR élevé, Position élevée / CTR faible, Position basse / CTR élevé , Position basse / CTR faible
Finalement que penser de cette première édition
S'il fallait résumer ce Google Search Central Paris 2026, je dirais qu'il s'agissait davantage d'une opération de "rassurage" institutionnel que d'une véritable révolution d'informations. Pour les 200 acteurs du secteur présents, le bilan est contrasté.
D'un côté, nous avons reçu une confirmation précieuse : Google est pleinement conscient de la crise de confiance qui frappe Discover en France. La transparence affichée par les équipes sur le sujet du spam et la reconnaissance du rôle des ingénieurs dans le traitement des feedbacks utilisateurs sont des signaux positifs.
De l'autre, nous restons sur notre faim concernant les chantiers qui nous (pré)occupent le plus. Entre le silence total concernant le déploiement d'AIO/AIM en France et l'absence de roadmap claire, on ne peut manquer de se demander pourquoi organiser cet évènement à ce moment précis sans avoir rien à annoncer, pas même une nouvelle fonctionnalité.
J'espère vraiment qu'un tel évènement aura lieu de nouveau à l'avenir, mais dans une forme plus proche de celle de Zurich, plus tournée vers l'inspiration et les nouvelles fonctionnalités. J'ai le souvenir d'événements qui se tenaient régulièrement chez Google France il y a une dizaine d'années, dont une conférence très marquante de Richard Gingras en 2014 et qui apportaient beaucoup de valeur.
Je me souviens également de la conférence de Matt Cutts à Paris en 2010.
C'est à mon avis la voie à suivre pour restaurer un dialogue entre Google et les éditeurs en France, indépendamment des échanges juridiques.
Commentaires
commentaire